(BI) Business Intelligence
- (BI) Business Intelligence
- Data Warehouse
- Datamart
Power BISSAS(SQL Server Analytic Services)SSRS(SQL Server Reporting Services)SSIS(SQL Server Integration Services)ETL(Extract-Transform-Load)Cube/Hypercube/OLAPQlik
Références



L'actualité
-
Le robot Pepper, nid à vulnérabilités de sécurité

Des chercheurs danois et suédois en sciences informatiques et systèmes autonomes ont décortiqué la sécurité...
-
Nvidia réunit IA et HPC dans sa HGX-2...

Nvidia se prépare à livrer la plate-forme serveur HGX-2 qui sera capable d'exploiter la puissance de 16 GPU Tesla V100...
-
L'Ecole du numérique forme des managers...

L'EMD, une école de commerce située � Marseille ouvre à la prochaine rentrée l'école du numérique...
Parcours & Expérience
Librairie








L'information



(BI) Business Intelligence
Business Intelligence (BI) ou Decision Support System (DSS))
est l'informatique à l'usage des décideurs et des dirigeants d'entreprises.
Elle désigne les moyens, les outils et les méthodes qui permettent de collecter,
consolider, modéliser et restituer les données, matérielles ou immatérielles,
d'une entreprise en vue d'offrir une aide à la décision et de permettre à
un décideur d'avoir une vue d'ensemble de l'activité traitée. Ce type d'application repose sur une architecture commune dont les bases théoriques viennent principalement de R. Kimball, B. Inmon et D. Linstedt.
-
Les données opérationnelles sont extraites périodiquement de sources hétérogènes :
fichiers plats, fichiers Excel, base de données (
DB2, Oracle, SQL Server, etc...), service web, données massives et stockées dans un entrepôt de données. - Les données sont restructurées, enrichies, agrégées, reformatées, nomenclaturées pour être présentées à l'utilisateur sous une forme sémantique (vues métiers ayant du sens) qui permet aux décideurs d'interagir avec les données sans avoir à connaître leur structure de stockage physique , de schémas en étoile qui permettent de répartir les faits et mesures selon des dimensions hiérarchisées, de rapports pré-préparés paramétrables, de tableaux de bords plus synthétiques et interactifs.
- Ces données sont livrées aux divers domaines fonctionnels (direction stratégique, finance, production, comptabilité, ressources humaines, etc...) à travers un système de sécurité ou de datamart spécialisés à des fins de consultations, d'analyse, d'alertes prédéfinies, d'exploration de données, etc...
L'informatique décisionnelle s'insère dans l'architecture plus large d'un système d'information mais n'est pas un concept concurrent du management du système d'information. Au même titre que le management relève de la sociologie et de l'économie, la gestion par l'informatique est constitutive de deux domaines radicalement différents que sont le management et l'informatique. Afin d'enrichir le concept avec ces deux modes de pensées, il est possible d'envisager un versant orienté ingénierie de l'informatique portant le nom d'informatique décisionnelle, et un autre versant servant plus particulièrement les approches de gestion appelé management du système d'information.
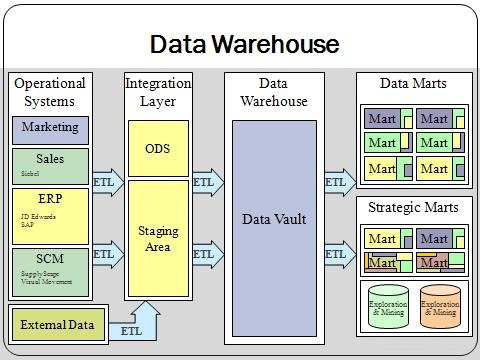
Data Warehouse
|
Un Entrepôt de données est une base de données regroupant une
partie ou l'ensemble des données fonctionnelles d'une entreprise.
Il entre dans le cadre de l'informatique décisionnelle ; son but est
de fournir un ensemble de données servant de référence unique,
utilisée pour la prise de décisions dans l'entreprise par le biais
de statistiques et de rapports réalisés via des outils de reporting.
D'un point de vue technique, il sert surtout à 'délester' les bases
de données opérationnelles des requêtes pouvant nuire à
leurs performances.
|

|
- L'architecture de haut en bas : selon Bill Inmon, l'entrepôt de données est une base de données au niveau détail, consistant en un référentiel global et centralisé de l'entreprise. En cela, il se distingue du Datamart, qui regroupe, agrège et cible fonctionnellement les données.
- L'architecture de bas en haut : selon Ralph Kimball, l'entrepôt de données est constitué peu à peu par les Datamarts de l'entreprise, regroupant ainsi différents niveaux d'agrégation et d'historisation de données au sein d'une même base.
Datamart
Techniquement, c'est une base de données relationnelle utilisée en informatique décisionnelle et exploitée en entreprise pour restituer des informations ciblées sur un métier spécifique, constituant pour ce dernier un ensemble d'indicateurs utilisés pour le pilotage de l'activité et l'aide à la décision.
Power BI
Microsoft Power BI est une suite d'outils analytiques Business Intelligence permettant
aux entreprises d'agréger et d'analyser des données, mais aussi de partager de façon
sécurisée les informations (insights) dégagées par le biais de ces analyses
sous la forme de tableaux de bord. Cette solution met l'accent sur le self-service pour permettre à tous les employés de comprendre les données et de les exploiter. Elle permet par ailleurs d'unifier toutes les sources de données. |

|
SSAS (SQL Server Analytic Services)
SQL Server Analysis Services (SSAS) est un service apparu sous SQL Server 7,
connu à cette époque sous le nom de OLAP Services.Il permet de générer des cubes OLAP, données agrégées et multidimensionnelles.
Il permet également d'implémenter des algorithmes de Data Mining. |

|
SSRS (SQL Server Reporting Services)
Ce service apparu sous SQL Server 2000 est un moteur de génération d'états.Deux services web le composent, l'un permettant son administration, l'autre la génération, l'abonnement, le rendu des rapports. Les rendus se font sous Excel, PDF, HTML, et Word (à partir de la version 2008). |

|
SSIS (SQL Server Integration Services)
SQL Server Integration Services est un composant du logiciel de base
de données Microsoft SQL Server qui peut être utilisé
pour effectuer un large éventail de tâches de migration de données.
SSIS est une plate-forme pour les applications d'intégration de
données et de workflow.SSIS est conçue pour créer des solutions d'intégration
de données à hautes performances, notamment des packages d'extraction,
de transformation et de chargement (ETL) pour l'entreposage de
données. |

|
ETL (Extract-Transform-Load)
Extract-Transform-Load (ETL), ou extracto-chargeur, (ou parfois : datapumping). Il s'agit d'une technologie informatique intergicielle (comprendre middleware) permettant d'effectuer des synchronisations massives d'information d'une source de données (le plus souvent une base de données) vers une autre. Selon le contexte, on est amené à exploiter différentes fonctions, souvent combinées entre elles : "extraction", "transformation", "constitution" ou "conversion", "alimentation". |

|
Oracle ou SAP...),
des transformateurs qui manipulent les données (agrégations, filtres, conversions...),
et des mises en correspondance (mappages). L'objectif est l'intégration ou la réexploitation
de données d'un réservoir source dans un réservoir cible. À l'origine, les solutions
ETL sont apparues pour le chargement régulier de
données agrégées dans les entrepôts de données (ou datawarehouses),
avant de se diversifier vers les autres domaines logiciels. Ces solutions sont largement utilisées
dans le monde bancaire et financier, ainsi que dans l'industrie, au vu de la multiplication des nombreuses interfaces. Cube / Hypercube / OLAP
En informatique, et plus particulièrement dans le domaine des bases de données,
le traitement analytique en ligne (OnLine Analytical Processing, OLAP)
est un type d'application informatique orienté vers l'analyse sur-le-champ d'informations
selon plusieurs axes, dans le but d'obtenir des rapports de synthèse tels que ceux
utilisés en analyse financière.Les applications de type OLAP sont couramment utilisées en informatique
décisionnelle, dans le but d'aider la direction à avoir une vue transversale
de l'activité d'une entreprise. |

|
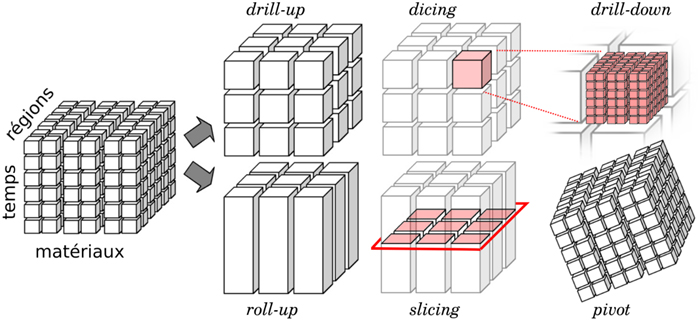
hypercube OLAP donne accès à des fonctions d'extraction de l'information
(pour visualisation, analyse ou traitement), et à des fonctions de requête en langage MDX
(comparable à SQL pour une base de données relationnelles).
Les résultats d'une requête sont principalement lus en 2 dimensions maximum (tableau).- Rotate (ou Pivot) : sélection du couple de dimensions qui formera le résultat de la requête,
- Slicing : extraction d'une tranche d'information,
- Scoping (ou Dicing) : extraction d'un bloc de données (opération plus générale que le slicing),
- Drill-up : synthèse des informations en fonction d'une dimension (exemple de drill-up sur l'axe temps : passer de la présentation de l'information jour par jour sur une année, à une valeur synthétique pour l'année),
- Drill-down : c'est l'équivalent d'un "zoom", opération inverse du drill-up,
- Drill-through : lorsqu'on ne dispose que de donnéagrégées (indicateurs totalisés), le drill through permet d'accéder au détail élémentaire des informations (voir notamment les outils H-OLAP).
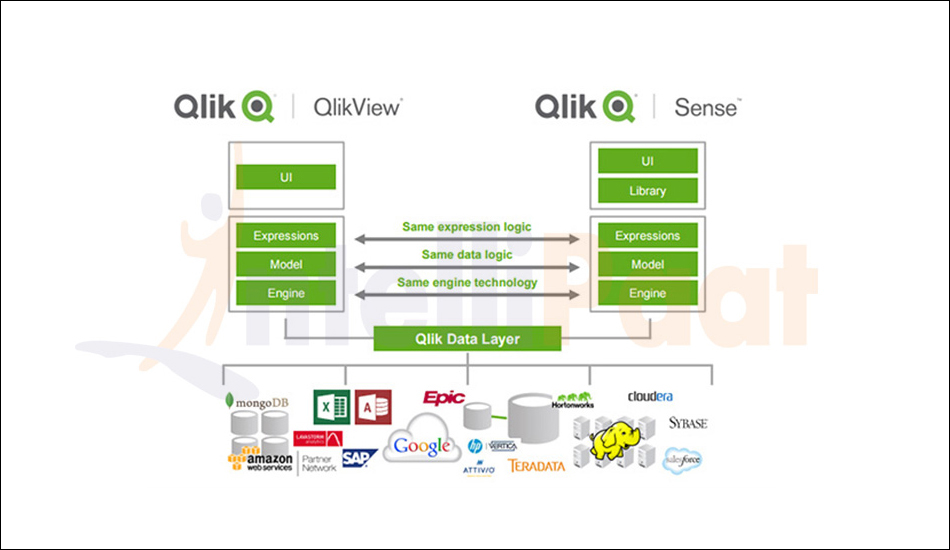
Qlik
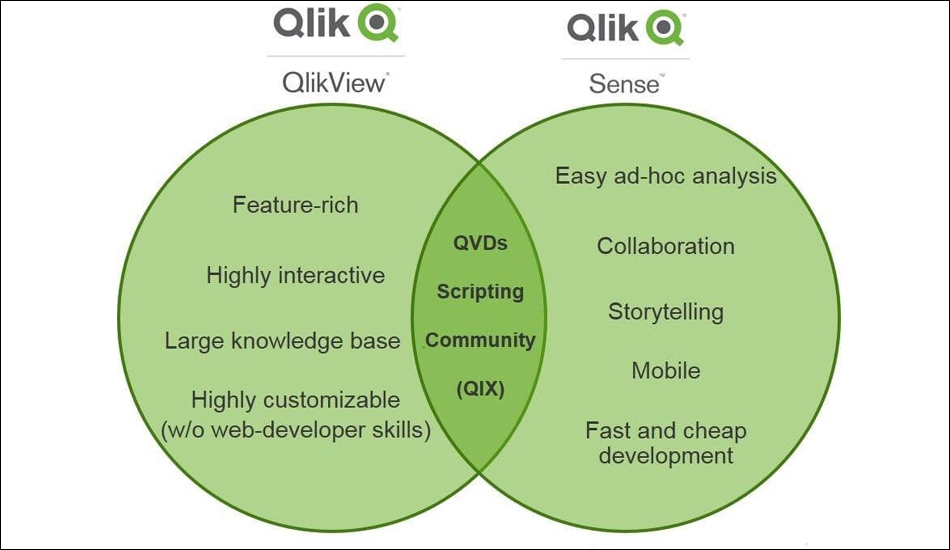
QlikView et QlikSense ont des objectifs différents qui s'exécutent sur le même moteur.
Dans QlikView, l'utilisateur s'acquitte de ses tâches quotidiennes en analysant les données à l'aide
d'un tableau de bord légèrement configurable.La plupart des données sont en quelque sorte "prédéfinies". D'autre part, QlikSense permet d'associer différentes sources de données et de configurer complètement
les visualisations, permettant ainsi de suivre un chemin de découverte individuel à travers les données. |

|
QuikView. "Quik" synonyme de "Qualité,
de la Compréhension, de l'Interaction, de la Connaissance." Initialement, le logiciel
a été vendu seulement en Suède.Qlik (précédemment connu sous le nom QlikTech) a été fondée à Lund, en Suède en 1993. C'est une société de logiciels de business intelligence (BI).