Parcours & Expérience
De 2011 à 2013 : Conseil d'État - Juridiction administrative (Paris)
- Développement d'un logiciel permettant la gestion et la dématérialisation de dossiers contentieux administratifs à l'usage des tribunaux administratifs français (GED).
- Développement C# / ASP.NET / MVC / IoC / ORM / Web Services / XML / JSON / etc...
- Quality Assurance : Test Unitaire & d'intégration (Moq) / Automatisation des tests E2E (Selenium).
- Aux sein d'un team (1 CP-IT, 2 Lead Tech, 12 Développeurs C#, 5 Analystes, 2 ingénieur QA) l'ensemble rattaché à la DSI et au pôle QA.
- Travail en mode Agile, découpage en RM de 8 semaines, chaque RM découpée en sprint de 2 semaines. Sprint Planning Meeting (4h) / Standup du matin (10mn), retro de fin de sprint (3h).
Principales fonctions :
- Développement :
- C# / ASP.NET / MVC / IoC / ORM / Web Services / XML / JSON / etc...
- Prise en compte des PBI(s)
- MCO / TMA
- Quality Assurance :
- Test Unitaire & d'intégration (Moq) / Automatisation des tests E2E (Selenium)
- Dérouler des MAT(s) et des TNR(s)
- Vérification de la cohérence et de l'intégrité des données en base Oracle
- Veille des résultats et archives
- Revues de codes / Clean code / Refactoring / Dettes techniques
Team
- 1 CP-IT
- 2 Tech Lead
- 12 Dev C#
- 2 Testeurs QA
- 5 Analystes
Environnement
- DEV
- TEST
- UAT
- PRE-PROD
- PROD
SGBDR
Architecture
CI/CD
ARAMIS
Le projet Aramis s'inscrit dans le cadre général de l'effort de modernisation de l'administration par l'utilisation des nouvelles technologies d'information et de communication. Son principal objet vise à dématérialiser le cycle complet de traitement d'un dossier du contentieux administratif, de l'enregistrement des recours à la notification des décisions et à l'archivage des dossiers, ainsi que le cycle complet d'élaboration des projets de jugement. Le Conseil d'État est chargé d'assurer la gestion des 8 cours administratives d'appel, des 42 tribunaux administratifs et de la Cour nationale du droit d'asile.
Contexte global du projet
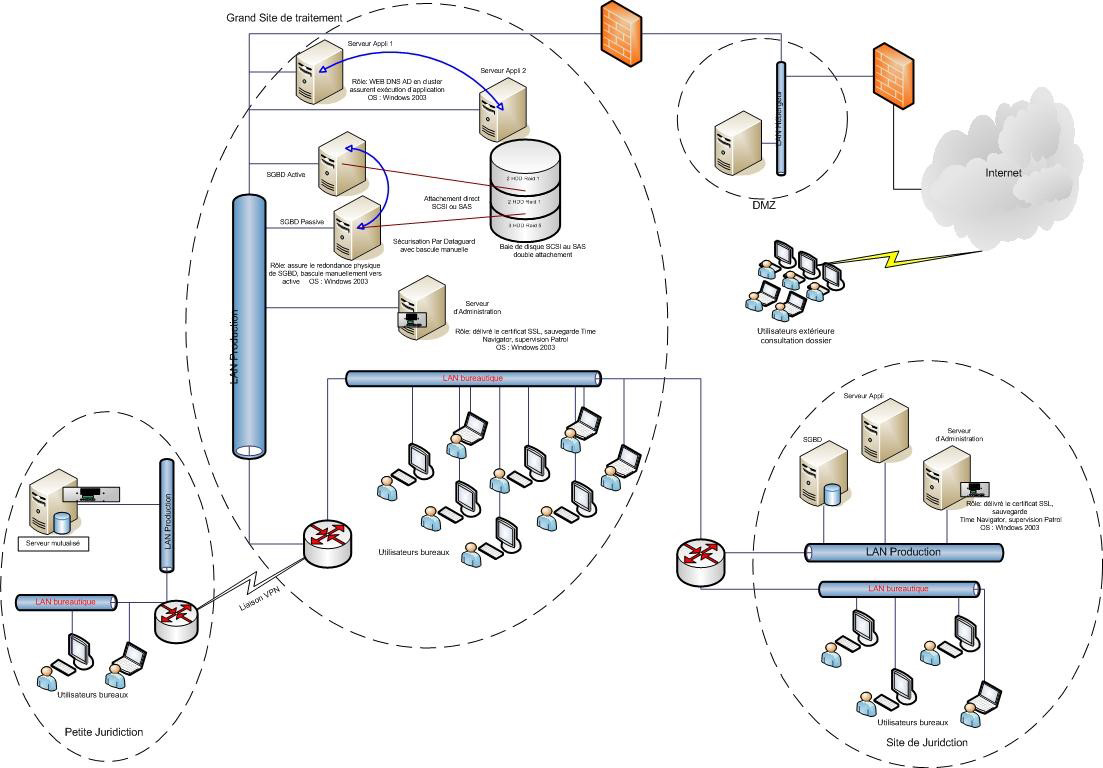
L'objectif du projet ARAMIS consiste en la refonte et l'unification de toutes les applications relatives à la gestion informatisée des activités contentieuses au Conseil d'Etat, dans les cours administratives d'appel, dans les tribunaux administratifs et à la Cour Nationale du droit d'asile. Cette gestion sera distribuée sur 49 sites physiques dont 40 en métropole et 9 en Outre-mer. Cet ensemble de sites est réparti selon 3 catégories.
Le site central (1 instance)
Une ferme de deux serveurs applicatifs en répartition de charge pour les web services.
1 serveur de données Oracle protégé par une base de secours (DataGuard) sur un autre serveur.
Ce serveur de données de secours permet de sécuriser les données et en cas de problème d'avoir un temps d'interruption de service extrêmement réduit.
Un mécanisme de pare-feu permettant de protéger l'accès aux données sensibles hébergées sur le site.
Un serveur d'administration accueillant les services d'authentification, le service de sauvegarde, le serveur de supervision, le gestionnaire de certificat.
Les sites des juridictions (48 instances)
Sur les sites des juridictions, on retrouve l'ensemble des fonctions du site central. Seul le volume d'affaire et le nombre de connexions sont variables.
Sur les juridictions traitant de gros volumes de données, l'infrastructure déployée sera très proche de celle du site central.
On y retrouve notamment le serveur d'administration, le ou les serveurs d'applications, le ou les serveurs de base de données.
Dans le cas où l'on doit positionner deux serveurs SGBD, le même mécanisme de protection des données par technologie Dataguard pourra aussi être mis en oeuvre.
Le site démilitarisé DMZ (1 instance)
Sur le site DMZ, on positionne un serveur web, dont l'accès est sécurisé par un mécanisme de pare-feu.
Ce serveur aura la capacité d'interroger les serveurs d'applications du site central via des Web Services.
 Cette multiplicité des sites physiques et de leur type impose 4 contraintes directrices :
Cette multiplicité des sites physiques et de leur type impose 4 contraintes directrices :
- Utilisation de clients légers
- Autonomie des sites physiques
- Capacité à évoluer rapidement
- Distribution des bases de données
Solutions logicielles
Le Microsoft Framework .NET 3.5 gère tous les aspects de l'exécution d'une application dans un environnement d'exécution dit "managé" :- Allocation de la mémoire pour le stockage des données et des instructions du programme
- Autorisation ou refus des droits à l'application
- Démarrage et gestion de l'exécution
- Gestion de la réallocation de la mémoire pour les ressources qui ne sont plus utilisées
- NHibernate : est un Framework gérant la persistance des objets en base de données relationnelle.
- Log4NET : propose un ensemble d'API de gestion de traces.
- Spring.NET : est un conteneur dit " léger " : il prend en charge la création d'objets et la mise en relation d'objets par l'intermédiaire d'un fichier de configuration qui décrit les objets à fabriquer et les relations de dépendances entre ces objets.
- WCF : Windows Communication Foundation est une couche logicielle destinée à unifier les modes de communication propres aux composants COM+ et .NET.
- MSMQ : Microsoft Message Queue Server est une plateforme de gestion de messages (one-to-one ou multicast).
- Aspose.Words .NET : Aspose.Words est une bibliothèque de classes qui permet de réaliser un grand nombre de tâches de traitements sur des documents de types différents. Les formats pris en compte sont : DOC, OOXML, RTF, WordprocessingML, HTML, MHTML, TXT, OpenDocument etc...
- Aspose.PDF.kit pour .NET : Aspose.PDF.kit est composant .Net permettant d'effectuer de nombreuses manipulations des documents PDF.
- Moteur de fusion : Le moteur de fusion de skipper est utilisé directement dans ARAMIS. Son principe de fonctionnement est conservé.
- Serveur d'impression : Le serveur d'impression ne prend en compte que les documents au format PDF, les impressions se basant sur les fonctionnalités d'Acrobat Reader.
- AjaxControlToolkit : L'AJAXControlToolkit est un projet open source développé par les membres de la communauté ASP.NET mais aussi par l'équipe d'ASP.NET. Cette bibliothèque propose plus de 30 composants client Web tel que les accordéons, les calendriers, les filtres, les popups modales... Cette boite à outil à pour avantage d'éviter le recours au langage JavaScript de la part du développeur, celle-ci étant développée en C#.
- JQuery : JQuery est un Framework développé en JavaScript qui permet notamment de manipuler aisément la DOM, d'utiliser AJAX, de créer des animations...
- OpenSTA : OpenSTA est une solution Open Source d'injection de charge HTTP/HTTPS qui répond à ces besoins quelle que soit la technologie utilisée : J2EE, .NET, PHP, Ajax...
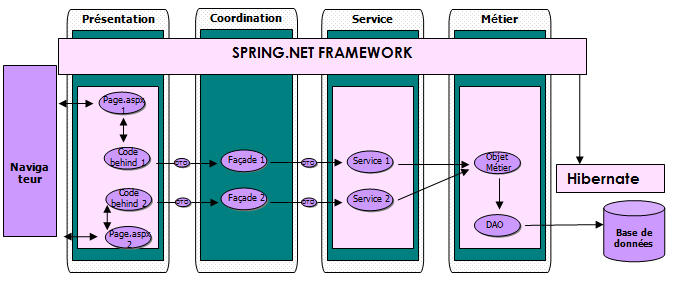
Architecture logicielle
Architecture multicouches :
L'architecture logicielle reposera sur 2 principes
- Une architecture multicouche afin de séparer la présentation, la coordination, les services métiers, les objets du domaine et la persistance de ces derniers (en base de données relationnelle), chacune d'elle ne connaissant que la couche qui lui est directement inférieure.
- Une architecture orientée services pour la communication inter/trans-site
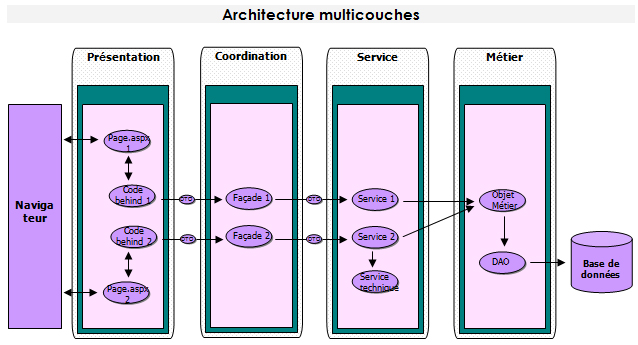
Couche " Présentation "
La couche présentation contient les écrans de l'application ainsi que tous les composants relatifs à l'IHM, elle est principalement composée des pages.
La couche présentation ne communique qu'avec la couche délégation, ainsi chaque page ne communique qu'avec les façades dont elle a besoin.
Cette couche reposera sur ASP.NET 2.0
Couche " Coordination "
La couche de coordination est composée de façades. Dans notre Framework, nous avons décidé de mettre en place des services qui contiennent l'implémentation métier
d'un appel à un service. La façade n'a qu'un rôle d'aiguillage des appels.
On rappelle succinctement les principes majeurs de ce pattern :
- La façade se charge d'effectuer les appels aux autres services métiers.
- Le passage de données en entrée/sortie est effectué à l'aide d'objets DTO.
- Eviter les problèmes de couplage entre la couche de présentation et les services métiers. En effet, si on laisse les pages appeler directement les services on obtient des dépendances très fortes et le système peut devenir difficilement évolutif.
- La façade peut appeler plusieurs services métiers. La façade récupère des DTO métier des services et retourne un DTO applicatif aux écrans.
Couche " Service "
Les services sont accédés via les façades. Ils ont pour but d'implémenter les méthodes que l'interface fonctionnelle déclare. Généralement, le service métier délègue à son tour à un objet du domaine implémentant le code. Il sera néanmoins possible qu'un service fasse interagir plusieurs objets au sein d'une même méthode lors d'implémentation ayant attrait à une logique de flux.
La couche Service ne communique qu'avec la couche Métier, ainsi chaque service ne communique qu'avec les objets métiers qu'elle doit manipuler.
Un service peut dans certain cas avoir besoin d'un service technique spécifique.
Le service peut aussi être hébergé sur un autre serveur web, au quel cas la couche " service WCF " s'occupera de la partie distribuée et communication.
Les services retournent un ou plusieurs DTO métier à la couche de façade.
Couche " Métier "
Les objets du domaine ont la responsabilité d'implémenter la logique du domaine de l'application.
La plupart des objets du domaine seront des objets persistants, sauvegardant leur état en base de données,
mais il est possible que certains objets n'est pas la nécessité d'être persistant.
Cette architecture est centrée sur les objets du domaine ou objets métiers. Le code métier est réalisé dans des méthodes de l'objet métier.
Un objet métier gère lui-même sa persistance en la délégant à son DAO.
Chaque objet métier ne communique qu'avec son DAO, et le DAO ne communique qu'avec la base de données.
La couche de persistance sera mise en oeuvre par le Framework NHibernate.
Le seul type d'objet transverse est le DTO qui est utilisé par les pages, les façades et les services.
C'est un objet sérialisable qui sert à transporter les données à travers les différentes couches.
Liaison et dépendances des couches
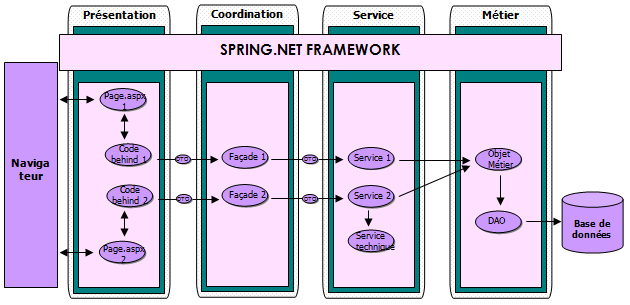
Design pattern IoC (inversion de control)
Les dépendances inter-couches sont assurées par le Framework Spring.Net.
Il prend en charge la création d'objets et la mise en relation d'objets par l'intermédiaire des fichiers de configuration (fichiers XML) qui décrivent les objets à fabriquer et les relations de dépendances entre ces objets.
Spring met en oeuvre le design pattern IoC (Inversion of Control) qui permet de gérer les dépendances entre les couches.
Mapping Hibernate
Hibernate est un Framework de mapping objet/relationnel. Cela veut dire qu'Hibernate nous permet de manipuler les données d'une base de données relationnelle sous forme d'objets.
Hibernate associe à chaque table relationnelle un objet métier (classe c# ou java). Cet objet métier aura exactement les mêmes attributs que la table mappée.
Un fichier XML appelé fichier de mapping Hibernate(.hbm) permet de décrire le mapping :
- La correspondance des attributs.
- Les contraintes liées à la table mappée (not null, clé primaire, etc...).
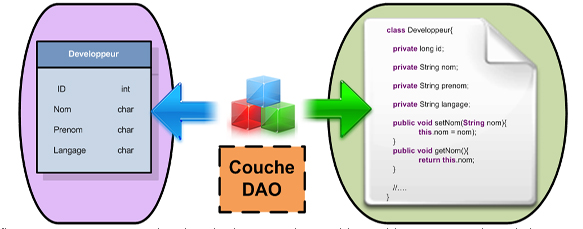
DAO (Data Access Object)
Le pattern DAO (Data Access Object) permet de faire le lien entre la couche métier et la couche persistante,
ceci afin de centraliser les mécanismes de mapping entre le système de stockage (base de données) et
les objets métier.
Il permet aussi de prévenir un changement éventuel de système de stockage de données (de PostgreSQL vers Oracle par exemple).
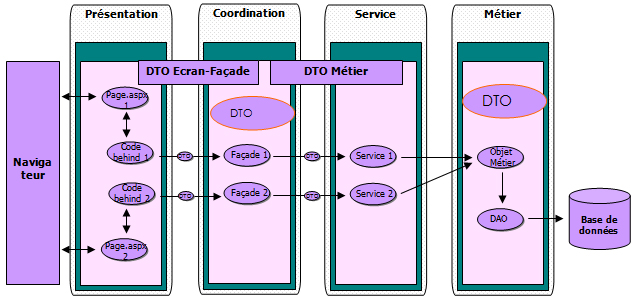
Design pattern DTO
Le DTO a pour but de transporter les données entre plusieurs sous-systèmes d'une application.
Le DTO ne contient aucun code métier. Il représente une vue sérialisable des données du domaine.
Les objets qui représentent les données de notre système de données sont les objets métier.
Or ces objets implémentent la logique métier de l'application.
Ces objets sont mappés en d'autre objets appelés DTO utilisé
uniquement pour transporter les informations entre les couches.
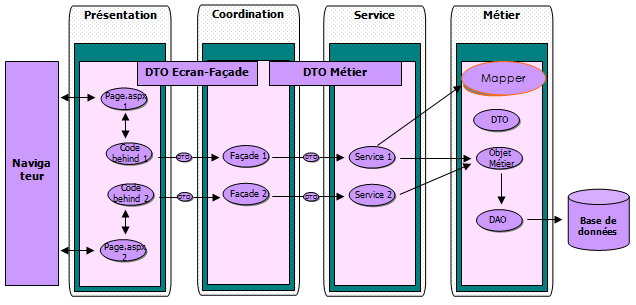
DTO -> métier : (Ecriture dans la base de données) : Lorsqu'on souhaite stocker les données saisies dans les IHMs de l'application (couche présentation),
on crée des objets DTO pour encapsuler ces données. Ce sont donc des objets DTO qui arrivent à la couche service en passant par la couche coordination.
Pour pouvoir stocker les informations véhiculées par ces objets DTO dans la base de données, il est nécessaire de les transformer en objets
métier car c'est ces derniers qui interagissent avec la base de données via les objets DAO. La couche service fait donc appel au mapper pour transformer
les objets DTO en objet métier.
Métier -> DTO : (Lecture dans la base de données) : Lorsqu'on souhaite afficher les données stockées dans la base de données,
on sollicite la couche façade dans la couche présentation. Dans la couche façade, on instancie des objets service qui, leurs tour, font appel aux
objets métier pour récupérer les informations dans la base de données. La couche métier renvoie donc à la couche service les
informations de la base de données stockées dans des objets métier. Or la couche service doit retourner à la couche façade des objets DTO.
La couche service fait donc appel aux mappers afin de transformer les objets métier en objets DTO.